Indexez un document
indexfile
POST https://bezillion.com/api/v1/indexfile?login=&password=
| login | Votre code d'identification. |
|---|---|
| password | Votre mot de passe. |
| multipart/form-data | |
| file | Contenu du document ou de l'image en binaire. |
| stored | Conserve une copie du texte. |
| ocr | Extraction du texte avec l'OCR. |
| lang | Langue du texte. |
| psm | Mode d'analyse du texte. |
| firstpage | Première page à traiter dans un PDF. |
| lastpage | Dernière page à traiter dans un PDF. |
| resolution | Résolution en dpi de l'image générée pour chaque page d'un PDF. |
| images | Extraction directe des seules images d'un PDF. |
| rotate | Rotation des images. |
| crop | Découper les images. Découper le texte en clair dans un PDF. |
| resize | Redimensionner les images. |
| negate | Inverser les couleurs. |
| normalize | Ajouter du contraste aux couleurs. |
| colorspace | Convertir en niveaux de gris. |
| unsharp | Accentuer les contours. |
| dots | Supprimer les points blancs. |
stored : 0 - ne garde pas une copie du texte extrait du document ou de l'image dans l'index. Sans une copie du texte, mettre en valeur des extraits dans une recherche est impossible.
lang - langue du texte : eng, fra, deu, spa, ita ou por.
Spécifiez plusieurs langues en les séparant par un +, e.g. fra+eng.
NOTE : L'ordre est important.
psm - Page Segmentation Mode :
1 - Automatic page segmentation with OSD (Orientation and Script Detection),
3 - Fully automatic page segmentation, but no OSD,
4 - Assume a single column of text of variable sizes,
6 - Assume a single uniform block of text).
ocr : 1 - force la lecture du texte en clair dans un PDF avec l'OCR.
Indiquez le mode d'extraction de chaque page d'un PDF :
firstpage : numéro de la première page à traiter,
lastpage : numéro de la dernière page à traiter,
resolution : résolution de l'image générée en dpi - 50, 75, 100, 125, 150 ou 200
-
IMPORTANT : Si une page ne contient qu'une image et aucun texte, l'image est systématiquement directement extraite du document,
images : 1 - extraire uniquement directement toutes les images.
Activez les options de traitement de chaque image avant analyse :
rotate : 180 pour retourner l'image, -90 ou 90 pour la tourner vers la gauche ou vers la droite,
crop - : limiter la lecture de l'image ou du texte à la zone spécifiée par une largeur et une hauteur séparées par un x à partir d'une position spécifiée par des coordonnées x et y précédées par un + en pixels pour la résolution donnée, e.g. 640x200+50+80,
resize - : redimensionner l'image de 50, 75, 125, 150 ou 200 %,
negate - : 1 - inverser les couleurs,
normalize - : 1 - ajouter du contraste aux couleurs,
colorspace - : 1 - convertir les couleurs en niveaux de gris,
unsharp - : 1 - accentuer les contours,
dots - : 1 - supprimer les points blancs.
IMPORTANT : Les options de traitement d'une image sont effectués dans l'ordre ci-dessus.
Pour avoir une bonne compréhension des effets de ces paramètres, testez-les dans l'interface de votre espace personnel.
jumps over
the lazy dog.
$ curl -s --fail --show-error -X POST "https://bezillion.com/api/v1/indexfile?login=abcdef&password=ABCDEF" -F "file=@fox.txt" -o -
{"status":"success","data":null}Recherchez le terme fox dans votre index :
The quick brown fox jumps over the lazy dog.
Obtenez le type MIME du fichier :
$ file -b --mime-type fox.odt
application/vnd.oasis.opendocument.textPassez le type MIME du fichier avec le contenu du document :
$ curl -s --fail --show-error -X POST "https://bezillion.com/api/v1/indexfile?login=abcdef&password=ABCDEF" -F "file=@fox.odt; type=application/vnd.oasis.opendocument.text" -o -
{"status":"success","data":null}Le texte du document est extrait avec Tika.
{kind=link}

$ curl -s --fail --show-error -X POST "https://bezillion.com/api/v1/indexfile?login=abcdef&password=ABCDEF" -F "lang=eng" -F "psm=6" -F "file=@fox.jpg" -o -
{"status":"success","data":null}Le texte de l'image est lu avec Tesseract en mode 6 - Assume a single uniform block of text - avec les données entraînées pour la langue anglaise.
{kind=link}

$ curl -s --fail --show-error -X POST "https://bezillion.com/api/v1/indexfile?login=abcdef&password=ABCDEF" -F "lang=eng+jpn+spa" -F "psm=6" -F "file=@sushi.png" -o -
{"status":"success","data":null}Le texte de l'image est lu avec Tesseract en mode 6 - Assume a single uniform block of text - avec les données entraînées pour les langues anglaise, japonaise et espagnole.
Recherchez le terme pollo dans votre index :
I eat すし y Pollo
Essayez de rechercher les termes eat ou すし:
I eat すし y Pollo

Ce PDF contient une image qui est à l'envers.
$ curl -s --fail --show-error -X POST "https://bezillion.com/api/v1/indexfile?login=abcdef&password=ABCDEF" -F "lang=eng" -F "psm=6" -F "rotate=180" -F "file=@xof.pdf" -o -
{"status":"success","data":null}L'image dans le PDF est automatiquement extraite telle quelle, retournée et lue avec Tesseract en mode 6 - Assume a single uniform block of text - avec les données entraînées pour la langue anglaise.


Ce PDF est le résultat de la fonction Imprimer dans un fichier du navigateur sur la page Mentions légales du site web Collaboractor. NOTE : Si vous téléchargez ce PDF dans l'interface de votre espace personnel, vous pouvez directement récupérer le texte en clair sans l'analyser.
$ curl -s --fail --show-error -X POST "https://bezillion.com/api/v1/indexfile?login=abcdef&password=ABCDEF" -F "file=@legal_fr.pdf" -o -
{"status":"success","data":null}Le texte est extrait du PDF avec Poppler. La disposition du texte est préservée. Les pages sont séparées par un 0xC (FORMFEED).
Comparez le résultat en forçant l'utilisation de l'OCR :
$ curl -s --fail --show-error -X POST "https://bezillion.com/api/v1/indexfile?login=abcdef&password=ABCDEF" -F "ocr=1" -F "lang=fra" -F "psm=6" -F "resolution=100" -F "file=@legal_fr.pdf" -o -
{"status":"success","data":null}Chaque page dans le PDF est convertie en une image avec Ghostscript avec une résolution de 100 dpi et lue avec Tesseract en mode 6 - Assume a single uniform block of text - avec les données entraînées pour la langue française. NOTE : Si vous exécutez la même opération dans l'interface de votre espace personnel, vous pouvez récupérer l'image de la première page et le texte lu par l'OCR.
Recherchez le terme legal dans votre index.
{kind=link}

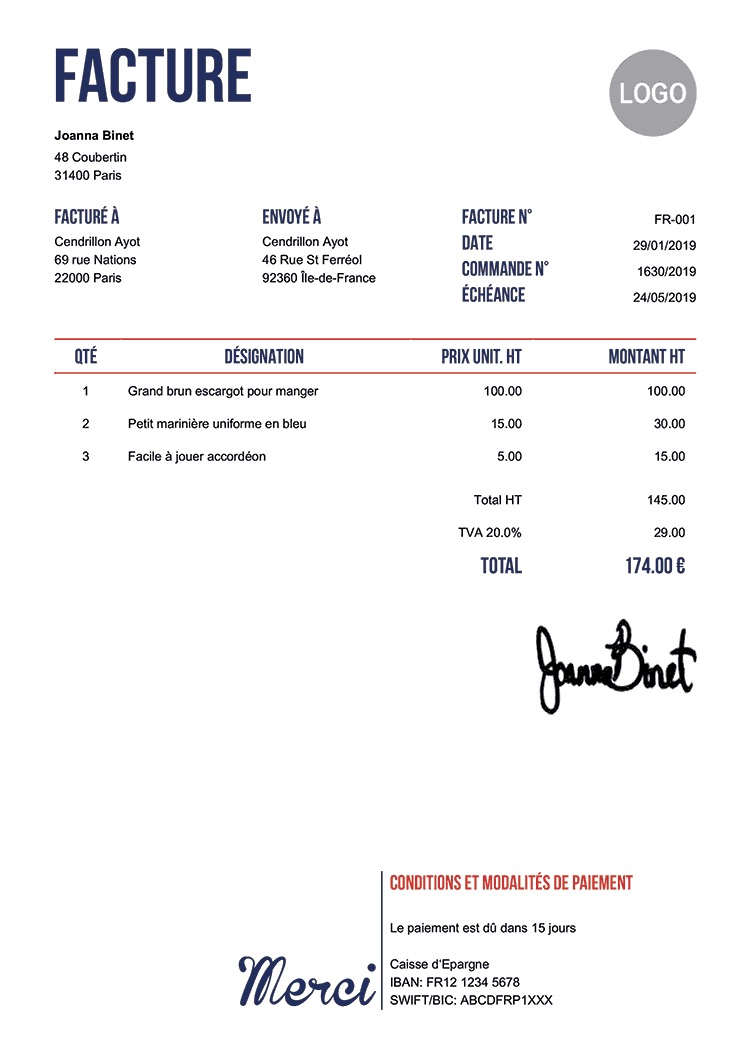
$ curl -s --fail --show-error -X POST "https://bezillion.com/api/v1/indexfile?login=abcdef&password=ABCDEF" -F "lang=fra" -F "psm=6" -crop="200x100+50+230" -F "resize=125" -F "unsharp=1" -F "file=@facture.png" -o -
{"status":"success","data":null}L'image est découpée autour de l'adresse de facturation, redimensionnée de 125 % avec une accentuation des contours et lue avec Tesseract en mode 6 - Assume a single uniform block of text - avec les données entraînées pour la langue française. NOTE : Si vous exécutez la même opération dans l'interface de votre espace personnel, vous pouvez vérifier le découpage de l'image.
Recherchez les termes +ayot +paris dans votre index :
Cendrillon Ayot 69 rue Nations 22000 Paris

Téléchargez le code des fonctions sendpost et file_mime_type de la librairie iZend.
Copiez les fichiers dans l'espace de votre application.
NOTE : Reportez-vous à la page Appelez l'API du service pour une description des fonctions sendpost et file_mime_type.
Ajoutez le fichier indexfile.php avec le contenu suivant :
- require_once 'sendhttp.php';
- require_once 'filemimetype.php';
Charge le code des fonctions sendpost et file_mime_type.
- function indexfile($login, $password, $file, $params=false) {
Définit la fonction indexfile.
$login est votre code d'identification. $password est votre mot de passe.
$file est le chemin d'accès du fichier à indexer.
$params est un tableau associatif contenant les noms et les valeurs des paramètres spécifiant le mode d'extraction de chaque page d'un PDF, les options de traitement de chaque image avant analyse, la langue du texte et le mode d'analyse du texte pour l'OCR, e.g. array('resize' => 125, 'psm' => 6, 'lang' => 'fra').
- $curl = 'https://bezillion.com/api/v1/indexfile' . '?' . 'login=' . urlencode($login) . '&' . 'password=' . urlencode($password);
Met $curl à l'URL de l'action indexfile de l'API avec le code d'identification et le mot de passe du compte de l'utilisateur.
$login et $password doivent être échappés.
- $files=array('file' => array('name' => basename($file), 'tmp_name' => $file, 'type' => file_mime_type($file)));
Prépare la liste des fichiers attachés au POST : file - le document à indexer avec le nom du fichier, le chemin d'accès au fichier et son type MIME.
- $response=sendpost($curl, $params, $files);
Envoie la requête HTTP avec sendpost.
Les arguments login et password sont déjà dans $curl.
- if (!$response) {
- return false;
- }
Si $response vaut false, le serveur est inaccessible,
indexfile retourne false.
- if ($response[0] == 200) {
- return true;
- }
Si $response[0] contient le code de retour HTTP 200 Ok,
indexfile retourne true.
- return false;
- }
Si $response[0] contient un code de retour HTTP autre que 200 Ok, une erreur d'exécution s'est produite.
indexfile retourne false.
EXEMPLE
En supposant que vous avez sauvé les fichiers sendhttp.php, filemimetype.php et indexfile.php dans le répertoire courant, lancez PHP en mode interactif, chargez la fonction indexfile et appelez-la avec votre code d'identification et votre mot de passe, le chemin d'accès à un fichier et d'autres options dans un tableau associatif en argument :
$ php -a
php > require_once 'indexfile.php';
php > $r=indexfile('abcdef', 'ABCDEF', 'fox.pdf', array('lang' => 'eng', 'psm' => 6));
php > echo $r ? 'Ok' : 'Ko';
php > Ok
php > quit
Commentaires
Pour ajouter un commentaire, cliquez ici.