Index a document
indexfile
POST https://bezillion.com/api/v1/indexfile?login=&password=
| login | Your identification code. |
|---|---|
| password | Your password. |
| multipart/form-data | |
| file | Content of the document or the image in binary. |
| stored | Keep a copy of the text. |
| ocr | Extract text with the OCR. |
| lang | Language of the text. |
| psm | Scan mode. |
| firstpage | First page to process in a PDF. |
| lastpage | Last page to process in a PDF. |
| resolution | Resolution in dpi of the image generated for each page of a PDF . |
| images | Directly extract just the images in a PDF. |
| rotate | Rotate images. |
| crop | Crop images. Cut the clear text in a PDF. |
| resize | Resize images. |
| negate | Revert colors. |
| normalize | Add contrast to the colors. |
| colorspace | Convert to grayscale. |
| unsharp | Sharpen the contours. |
| dots | Remove white dots. |
stored: 0 - don't keep a copy of the text extracted from the document or the image within the index. Without a copy of the text, highlighting excerpts in a search is not possible.
lang - language of the text: eng, fra, deu, spa, ita or por.
Specify several languages by separating them with a +, e.g. eng+fra.
NOTE: The order is important.
psm - Page Segmentation Mode:
1 - Automatic page segmentation with OSD (Orientation and Script Detection),
3 - Fully automatic page segmentation, but no OSD,
4 - Assume a single column of text of variable sizes,
6 - Assume a single uniform block of text).
ocr: 1 - force reading a PDF which contains plain text with the OCR.
Specify the extraction mode of each page of a PDF:
firstpage : number of the first page to process,
lastpage : number of the last page to process,
resolution : resolution of the image generated in dpi - 50, 75, 100, 125, 150 or 200
-
IMPORTANT: If a page contains only one image and no text, the image is systematically directly extracted from the document,
images : 1 - directly extract only the images.
Activate the processing options of each image before analysis:
rotate : 180 to flip the image, -90 to rotate it to the left or to the right,
crop - : limit reading the image or the text to the area specified by a width and a height separated by an x from a position specified by x and y coordinates preceded by a + in pixels for the given resolution, e.g. 640x200+50+80,
resize - : resize the image by 50, 75, 125, 150 or 200 %,
negate - : 1 - revert colors,
normalize - : 1 - add contrast to the colors,
colorspace - : 1 - convert the image to grayscale,
unsharp - : 1 - sharpen the contours,
dots - : 1 - remove white dots.
IMPORTANT: Image processing options are run in the above order.
To have a correct understanding of the effects of these parameters, test them in the interface of your personal space.
jumps over
the lazy dog.
$ curl -s --fail --show-error -X POST "https://bezillion.com/api/v1/indexfile?login=abcdef&password=ABCDEF" -F "file=@fox.txt" -o -
{"status":"success","data":null}Look for the term fox in your index:
The quick brown fox jumps over the lazy dog.
Get the MIME type of the file:
$ file -b --mime-type fox.odt
application/vnd.oasis.opendocument.textPass the MIME type of the file with the content of the document:
$ curl -s --fail --show-error -X POST "https://bezillion.com/api/v1/indexfile?login=abcdef&password=ABCDEF" -F "file=@fox.odt; type=application/vnd.oasis.opendocument.text" -o -
{"status":"success","data":null}The text of the document is extracted with Tika.
{kind=link}

$ curl -s --fail --show-error -X POST "https://bezillion.com/api/v1/indexfile?login=abcdef&password=ABCDEF" -F "lang=eng" -F "psm=6" -F "file=@fox.jpg" -o -
{"status":"success","data":null}The text of the image is read with Tesseract in mode 6 - Assume a single uniform block of text - with the trained data for the English language.
{kind=link}

$ curl -s --fail --show-error -X POST "https://bezillion.com/api/v1/indexfile?login=abcdef&password=ABCDEF" -F "lang=eng+jpn+spa" -F "psm=6" -F "file=@sushi.png" -o -
{"status":"success","data":null}The text of the image is read with Tesseract in mode 6 - Assume a single uniform block of text - with the trained data for the English, the Japanese and the Spanish language.
Look for the term pollo in your index:
I eat すし y Pollo
Try looking for the terms eat or すし:
I eat すし y Pollo

This PDF contains an image which is upside down.
$ curl -s --fail --show-error -X POST "https://bezillion.com/api/v1/indexfile?login=abcdef&password=ABCDEF" -F "lang=eng" -F "psm=6" -F "rotate=180" -F "file=@xof.pdf" -o -
{"status":"success","data":null}The image in the PDF is automatically extracted as is, flipped and read with Tesseract in mode 6 - Assume a single uniform block of text - with the trained data for the English language.


This PDF is the result of the Print in a file function of the navigator on the page Legal information of the website Collaboractor. NOTE: If you upload this PDF in the interface of your personal space, you can directly retrieve the plain text it contains without analyzing it.
$ curl -s --fail --show-error -X POST "https://bezillion.com/api/v1/indexfile?login=abcdef&password=ABCDEF" -F "file=@legal_en.pdf" -o -
{"status":"success","data":null}The text is extracted from the PDF with Poppler. The layout of the text is preserved. The pages are separated by a 0xC (FORMFEED).
Compare the result by forcing the usage of the OCR:
$ curl -s --fail --show-error -X POST "https://bezillion.com/api/v1/indexfile?login=abcdef&password=ABCDEF" -F "ocr=1" -F "lang=eng" -F "psm=6" -F "resolution=100" -F "file=@legal_en.pdf" -o -
{"status":"success","data":null}Each page in the PDF is converted in an image with Ghostscript wit a resolution of 100 dpi and read with Tesseract in mode 6 - Assume a single uniform block of text - with the trained data for the English language. NOTE: If you run the same operation in the interface of your personal space, you can retrieve the image of the first page and the text read by the OCR.
Look for the term legal in your index.
{kind=link}

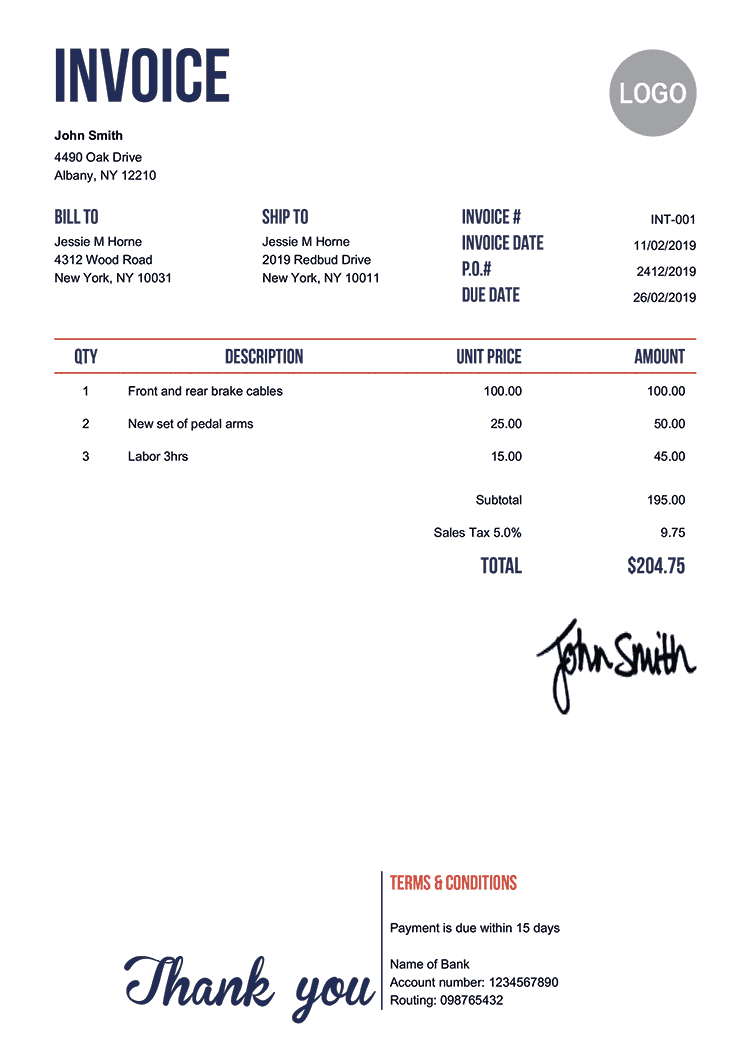
$ curl -s --fail --show-error -X POST "https://bezillion.com/api/v1/indexfile?login=abcdef&password=ABCDEF" -F "lang=eng" -F "psm=6" -crop="200x100+50+230" -F "resize=125" -F "unsharp=1" -F "file=@invoice.png" -o -
{"status":"success","data":null}The image is cropped around the billing information, resized to 125% with sharpened contours and read with Tesseract in mode 6 - Assume a single uniform block of text - with the trained data for the English language. NOTE: If you run the same operation in the interface of your personal space, you can check how the image is cropped.
Look for the terms +horne +"new york" in your index:
Jessie M Horne 4312 Wood Road New York, NY 10031

Download the code of the sendpost and file_mime_type functions from the iZend library.
Copy the files in the space of your application.
NOTE: See the page Call the service API for a description of the sendpost and file_mime_type functions.
Add the file indexfile.php with the following content:
- require_once 'sendhttp.php';
- require_once 'filemimetype.php';
Loads the code of the sendpost and file_mime_type functions.
- function indexfile($login, $password, $file, $params=false) {
Defines the function indexfile.
$login is your identification code. $password is your password.
$file is the pathname of file to index.
$params is an associative array containing the names and the values of the parameters specifying the extraction mode of each page of a PDF and the processing options of each image before analysis, the language of the text and the analysis mode of the text for the OCR, e.g. array('resize' => 125, 'psm' => 6, 'lang' => 'eng').
- $curl = 'https://bezillion.com/api/v1/indexfile' . '?' . 'login=' . urlencode($login) . '&' . 'password=' . urlencode($password);
Sets $curl to the URL of the indexfile action of the API with the identification code and the password of the user's account.
$login and $password must be escaped.
- $files=array('file' => array('name' => basename($file), 'tmp_name' => $file, 'type' => file_mime_type($file)));
Prepares the list of files attached to the POST: file - the document to index with the name of the file, the pathname of the file and its MIME type.
- $response=sendpost($curl, $params, $files);
Sends the HTTP request with sendpost.
The arguments login and password are already in $curl.
- if (!$response) {
- return false;
- }
If $response is false, the server is unreachable.
indexfile returns false.
- if ($response[0] == 200) {
- return true;
- }
If $response[0] contains the HTTP return code 200 Ok,
indexfile returns true.
- return false;
- }
If $response[0] contains an HTTP return code other than 200 Ok, an execution error has occurred.
indexfile returns false.
EXAMPLE
Assuming you have saved the files sendhttp.php, filemimetype.php and indexfile.php in the current directory, run PHP in interactive mode, load the indexfile function and call it with your identification code and password, the pathname of file and other options in an associative array in argument:
$ php -a
php > require_once 'indexfile.php';
php > $r=indexfile('abcdef', 'ABCDEF', 'fox.pdf', array('lang' => 'eng', 'psm' => 6));
php > echo $r ? 'Ok' : 'Ko';
php > Ok
php > quit
Comments
To add a comment, click here.